Understanding Overfitting in Machine Learning
One of the key objectives in machine learning is to develop models that generalize well to new, unseen data. However, a frequent challenge is overfitting, where a model becomes excessively tailored to the training data, capturing noise instead of the underlying pattern. This blog explores the concept of overfitting, the impact of data size on overfitting, and how regularization techniques can mitigate overfitting to create more robust models.
Building a Simple Regression Model
To illustrate overfitting, let's start with a simple regression problem. Suppose we observe a real-valued input variable
We generate synthetic data using the function
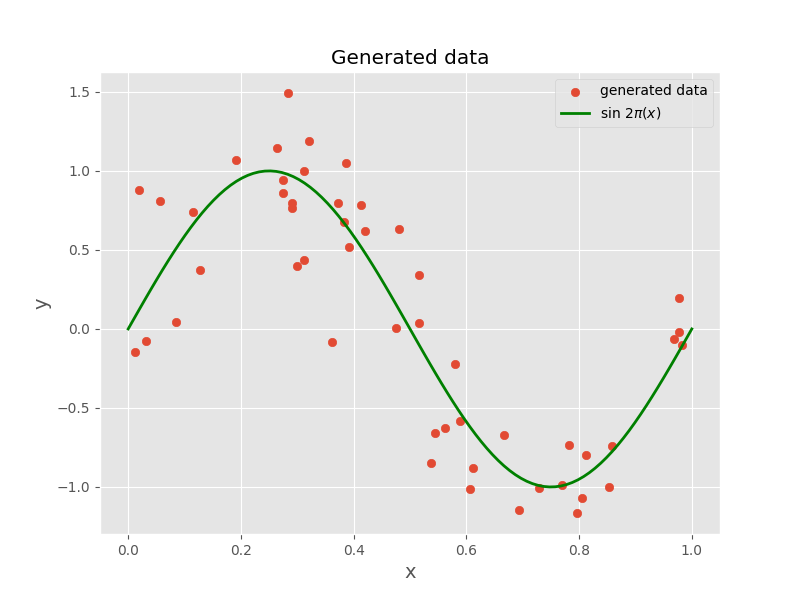
Our goal is to use this training set to predict the value
Curve Fitting with Polynomial Functions
We will approach this problem by fitting the data using a polynomial function of the form:
where
Here,
The solution to this curve fitting problem involves finding the value of
Exploring the Effect of Polynomial Order on Model Fit
To understand overfitting, we examine how the order of the polynomial affects model fit. We fit polynomials of different orders to the training data and observe the results. Additionally, we evaluate the models on new, unseen data to assess their generalization ability.
We start by dividing our data into training and test sets. The training set is used to fit the model, while the test set is used to evaluate the model's performance.
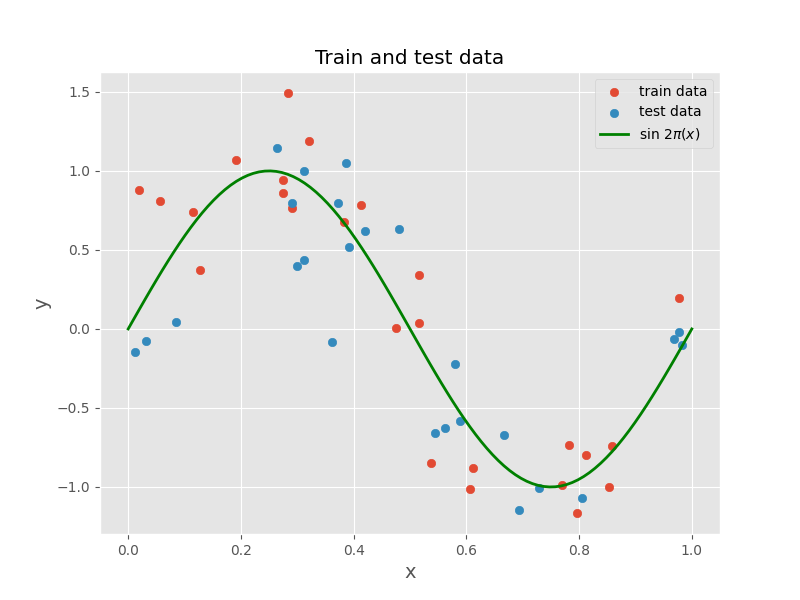
By fitting polynomials of varying orders to the training data and using the mean squared error (MSE) as our evaluation metric, we can observe how the model's complexity impacts its performance.
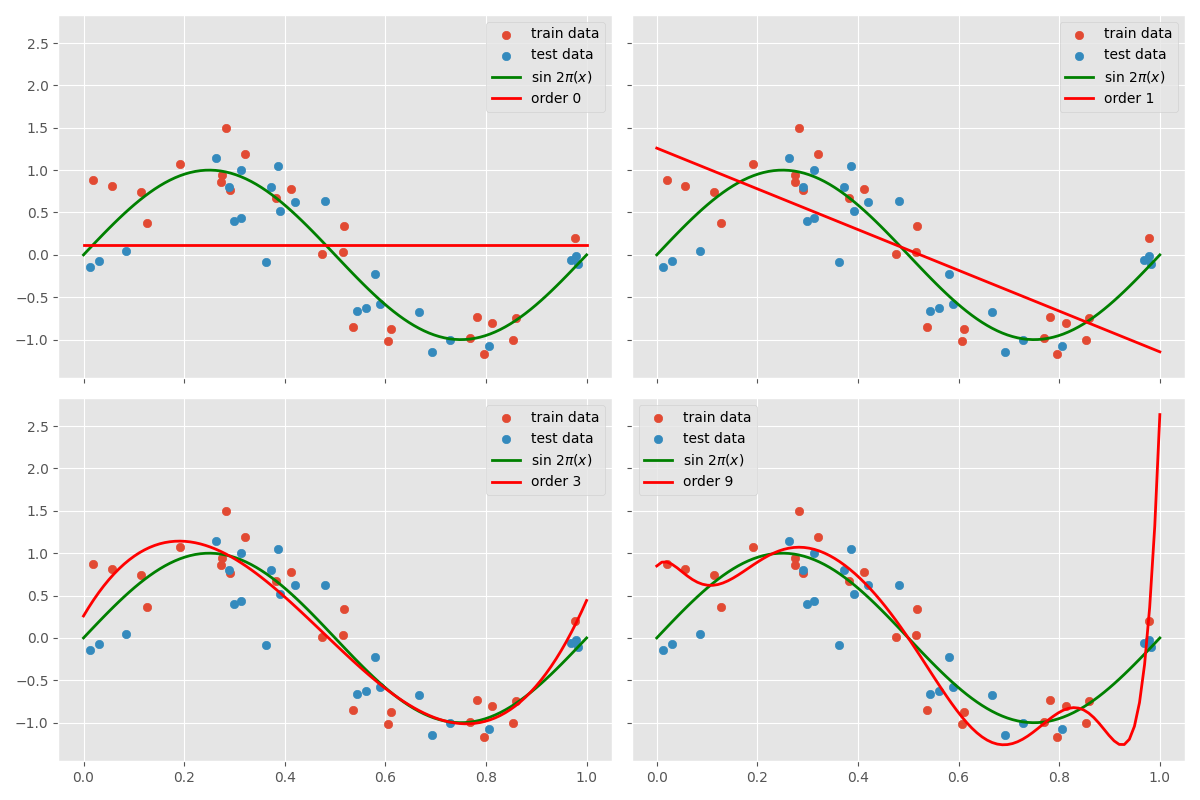
As the order of the polynomial increases, the model becomes more complex and fits the training data more closely. However, this increased complexity may lead to overfitting, where the model captures noise in the training data instead of the underlying pattern. In the plot above, the polynomial of order 9 oscillates excessively to capture the noise, whereas the polynomial of order 1 is too simple to capture the underlying pattern. The polynomial of order 3, on the other hand, seems to strike a balance by capturing the underlying pattern effectively.
Evaluating Model Performance
To further analyze the impact of polynomial order on model performance, we plot the training and test errors as a function of polynomial order. The training error decreases as the polynomial order increases because the model becomes more complex and fits the training data more closely. However, the test error initially decreases and then increases as the model becomes too complex and begins to overfit the training data. The optimal model complexity is the one that minimizes the test error, as it generalizes well to new data.
We use the root mean squared error (RMSE) as a metric for evaluating model performance, defined as the square root of the average of the squared differences (MSE) between the predicted values and the true values.
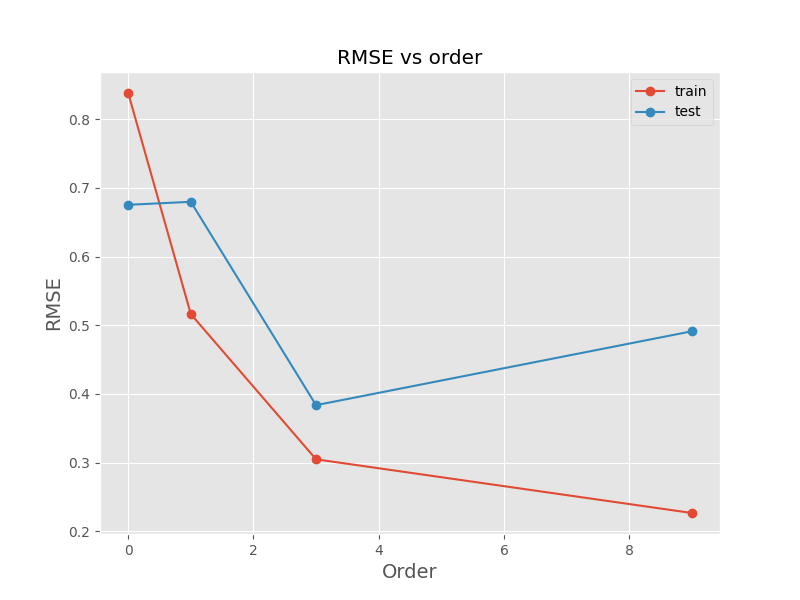
The plot above shows that the test error is minimized for a polynomial of order 3, which captures the underlying pattern without overfitting the training data. This demonstrates the trade-off between model complexity and generalization performance and highlights the importance of choosing the appropriate model complexity to avoid overfitting.
The output below summarizes the RMSE for different polynomial orders on both the training and test data:
Order: 0, RMSE (train): 0.8381, RMSE (test): 0.6753
Order: 1, RMSE (train): 0.5162, RMSE (test): 0.6796
Order: 3, RMSE (train): 0.3547, RMSE (test): 0.3835
Order: 9, RMSE (train): 0.2265, RMSE (test): 0.4911
As shown, the RMSE for the test data is minimized for a polynomial of order 3.
Analyzing Polynomial Coefficients
We can gain further insights by examining the coefficients of the polynomial for different orders:
Order: 0, Coefficients: [0.11941504]
Order: 1, Coefficients: [ 0.06102459 -1.15146493]
Order: 3, Coefficients: [-0.06511999 -2.69902699 0.36666158 2.55591654]
Order: 9, Coefficients:
[ 1.08414773e-02 -4.17947771e+00 -2.45869645e+00 7.26680257e+00
1.52424608e+01 9.83486762e+00 -2.99539542e+01 -3.50059274e+01
1.77062867e+01 2.17339983e+01]
As the polynomial order increases, the magnitude of the coefficients generally becomes larger. For the polynomial of order 9, the coefficients are finely tuned to the data, developing large positive and negative values to match each data point exactly.
Techniques to Reduce Overfitting
Increasing Data Size
One way to reduce overfitting is to use more data. As the number of data points increases, the model has more information to learn the underlying pattern, reducing the likelihood of overfitting. We can observe this by generating more data points and fitting polynomials of different orders to the new data.
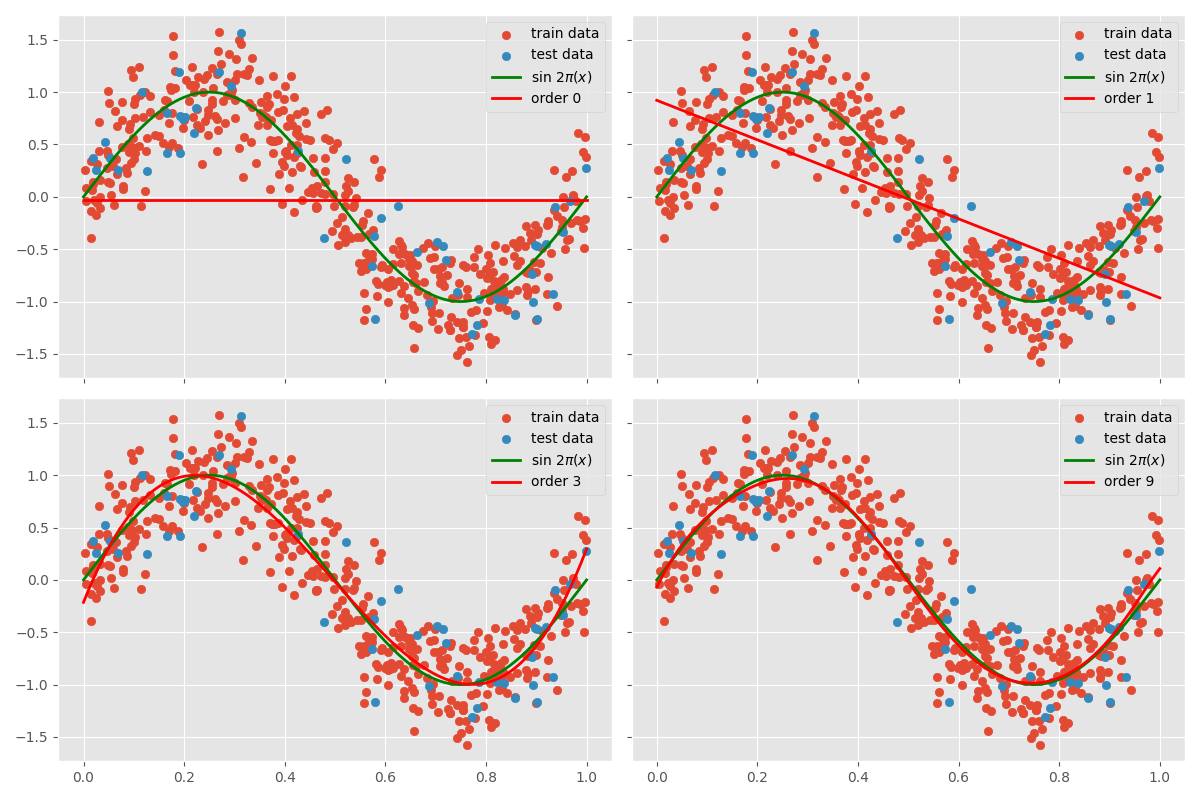
With more data points, the polynomial of order 9 fits the data more closely without overfitting, as it has more information to learn the underlying pattern. This highlights the importance of having sufficient data to train complex models.
Applying Regularization
Another effective technique to reduce overfitting is regularization, which adds a penalty term to the error function to discourage overly complex models. Regularization techniques, such as L1 and L2 regularization, penalize large coefficients and promote simpler models.
For example, L2 regularization modifies the error function as follows:
Here,
The Impact of Regularization
To see how regularization affects model complexity, we apply L2 regularization with different values of
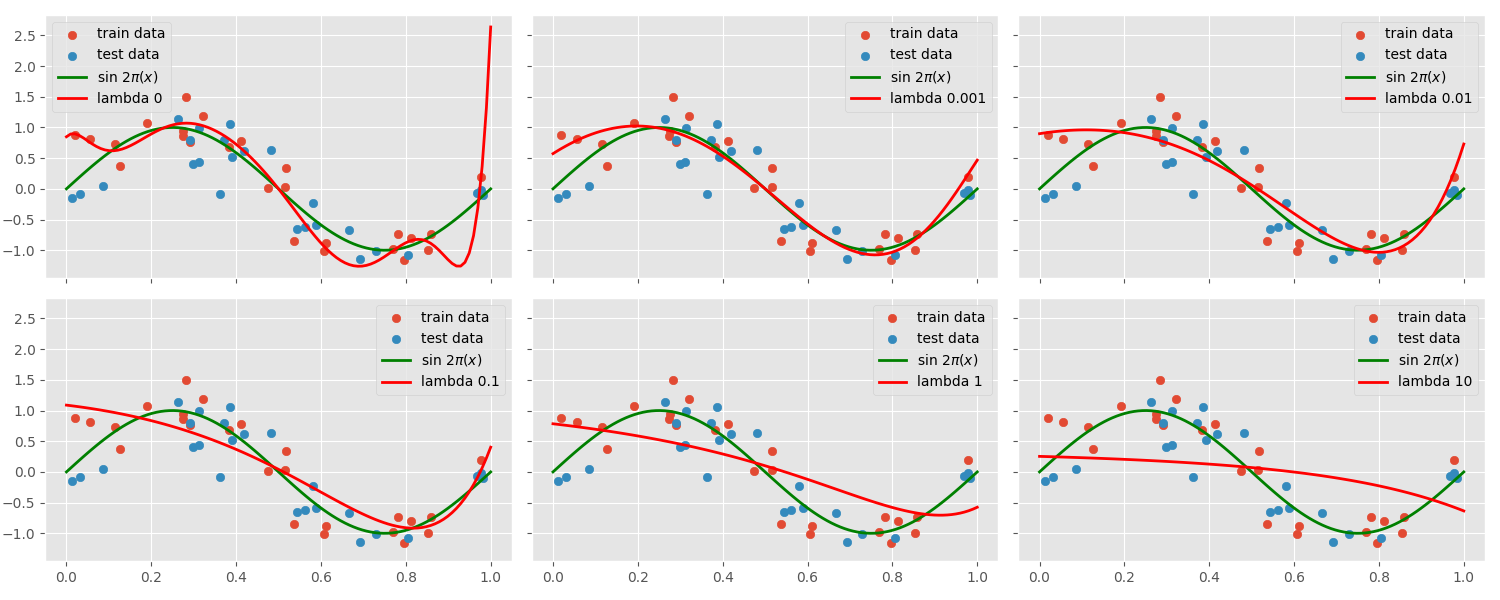
As
While regularization can help prevent overfitting, it is crucial to choose an appropriate value for
Conclusion
Overfitting is a common challenge in machine learning, where a model becomes too tailored to the training data, capturing noise instead of the underlying pattern. This can be mitigated by increasing the amount of training data and applying regularization techniques, such as L1 and L2 regularization, which penalize overly complex models. By selecting the appropriate model complexity and regularization parameters, we can create models that generalize well and are robust to noise in the training data.
Resources :
- [Pattern Recognition and Machine Learning-Bishop](Pattern Recognition and Machine Learning)
- code for generating the data and fitting the models can be found here